🧰 macOS virtual memory management APIs usage demo
This is a short post about using vm_* (vm_read, vm_write, vm_protect) APIs on macOS to patch a process at runtime.
The code is mostly based on Google Project Zero’s post - Fuzzing iOS code on macOS at native speed by Samuel Groß.
So let’s break it down.
Example app
This demo program runs indefinitely and performs addition on two user-provided integers, pretty straightforward:
// clang -o demo demo.c
//
#include <stdlib.h>
#include <stdio.h>
int add(int a, int b) {
return a + b;
}
int main(int argc, char **argv) {
for (;;) {
printf("[demo] Enter two numbers: ");
int a, b;
scanf("%d %d", &a, &b);
int res = add(a, b);
printf("[demo] %d + %d = %d\n", a, b, res);
}
return 0;
}
Let’s try to patch it to perform multiplication instead of addition.
First, let’s take a look at how add routine looks like in assembly (objdump -x86-asm-syntax=intel -D demo):
0000000100003ec0 <_add>:
100003ec0: 55 push rbp
100003ec1: 48 89 e5 mov rbp, rsp
100003ec4: 89 7d fc mov dword ptr [rbp - 4], edi
100003ec7: 89 75 f8 mov dword ptr [rbp - 8], esi
100003eca: 8b 45 fc mov eax, dword ptr [rbp - 4]
100003ecd: 03 45 f8 add eax, dword ptr [rbp - 8]
100003ed0: 5d pop rbp
100003ed1: c3 ret
100003ed2: 66 2e 0f 1f 84 00 00 00 00 00 nop word ptr cs:[rax + rax]
100003edc: 0f 1f 40 00 nop dword ptr [rax]
Everything that goes after ret instruction is basically just a nop (does nothing). It’s in there to ensure that the next function is aligned on a 16-byte boundary.
So, here we need to patch add instruction at 0x100003ecd with imul. One more thing to notice here is that x86_64 architecture, which my Mac uses, has variable-length instructions. add has the size of 3 bytes wherever imul is 4 bytes long - 0f af 45 f8. We can quickly verify this using rasm2 (part of radare2).
mbp:~ rasm2 -a x86 -b 64 "imul eax, dword ptr [rbp - 8]"
0faf45f8
But because we have the nop-s after the ret, we can safely overwrite them.
So, in the end, we need to patch these 3 instructions:
100003ecd: 03 45 f8 add eax, dword ptr [rbp - 8]
100003ed0: 5d pop rbp
100003ed1: c3 ret
with this (overwriting 1 byte of nop):
100003ecd: 0f af 45 f8 imul eax, dword ptr [rbp - 8]
100003ed1: 5d pop rbp
100003ed2: c3 ret
The patch
The full source code is available at GitHub - vm-demo. Let’s take a look at the most interesting parts.
-
First, we need to get a task port of our
demoprocess.kern_return_t kr; task_t task; kr = task_for_pid(mach_task_self(), pid, &task); if (kr != KERN_SUCCESS) { return; }For this to work our patcher (aka
runner), should be signed withcom.apple.security.cs.debuggerentitlement, and ourdemoshould also havecom.apple.security.get-task-allow. -
Next step is to find the base virtual address for the main image in our process (the first one found).
kern_return_t kr; vm_address_t image_addr = 0; int headers_found = 0; vm_address_t addr = 0; vm_size_t size; vm_region_submap_info_data_64_t info; mach_msg_type_number_t info_count = VM_REGION_SUBMAP_INFO_COUNT_64; unsigned int depth = 0; while (1) { kr = vm_region_recurse_64(task, &addr, &size, &depth, (vm_region_info_t)&info, &info_count); if (kr != KERN_SUCCESS) { break; } unsigned int header; vm_size_t bytes_read; kr = vm_read_overwrite(task, addr, 4, (vm_address_t)&header, &bytes_read); if (kr != KERN_SUCCESS) { printf("vm_read_overwrite failed\n"); exit(-1); } if (bytes_read != 4) { printf("[-] vm_read read to few bytes\n"); exit(-1); } if (header == MH_MAGIC_64) { headers_found++; } if (headers_found == 1) { image_addr = addr; break; } addr += size; }This code iterates over mapped memory regions using
vm_region_recurse_64. Reads 4 bytes from the region usingvm_read_overwrite. Compares those 4 bytes withMH_MAGIC_64(aka0xfeedfacf). If we have a match, then this is a validmach_header_64. And because we know that the process’s own image is mapped first, we can exit after the first successful attempt. -
The final step is to apply the patch.
unsigned int patch_offset = 0x3ecd; // offset of the `add` instruction vm_address_t patch_addr = image_addr + patch_offset; kern_return_t kr; kr = vm_protect(task, trunc_page(patch_addr), vm_page_size, false, VM_PROT_READ | VM_PROT_WRITE | VM_PROT_COPY); if (kr != KERN_SUCCESS) { printf("vm_protect failed\n"); return; } // 0f af 45 f8 imul eax, dword ptr [ebp - 8] // 5d pop ebp // c3 ret const char* code = "\x0f\xaf\x45\xf8\x5d\xc3"; kr = vm_write(task, patch_addr, (vm_offset_t)code, 6); if (kr != KERN_SUCCESS) { printf("vm_write failed\n"); return; } kr = vm_protect(task, trunc_page(patch_addr), vm_page_size, false, VM_PROT_READ | VM_PROT_EXECUTE); if (kr != KERN_SUCCESS) { printf("vm_protect failed\n"); return; }Here we use
vm_protectto change the permission of the particular page in virtual memory that we are interested in torw-(readable, writable, but non-executable) so we can write to it. After that,vm_writeis used to apply the patch. Andvm_protectis used one more time to revert the permissions back tor-e(readable and executable).
That’s basically it.
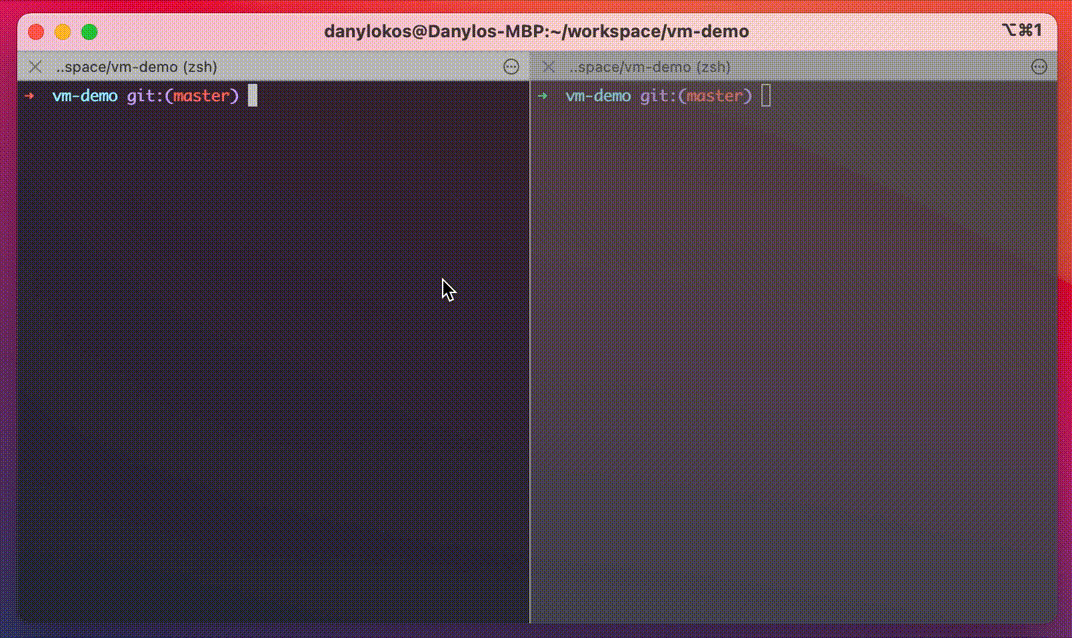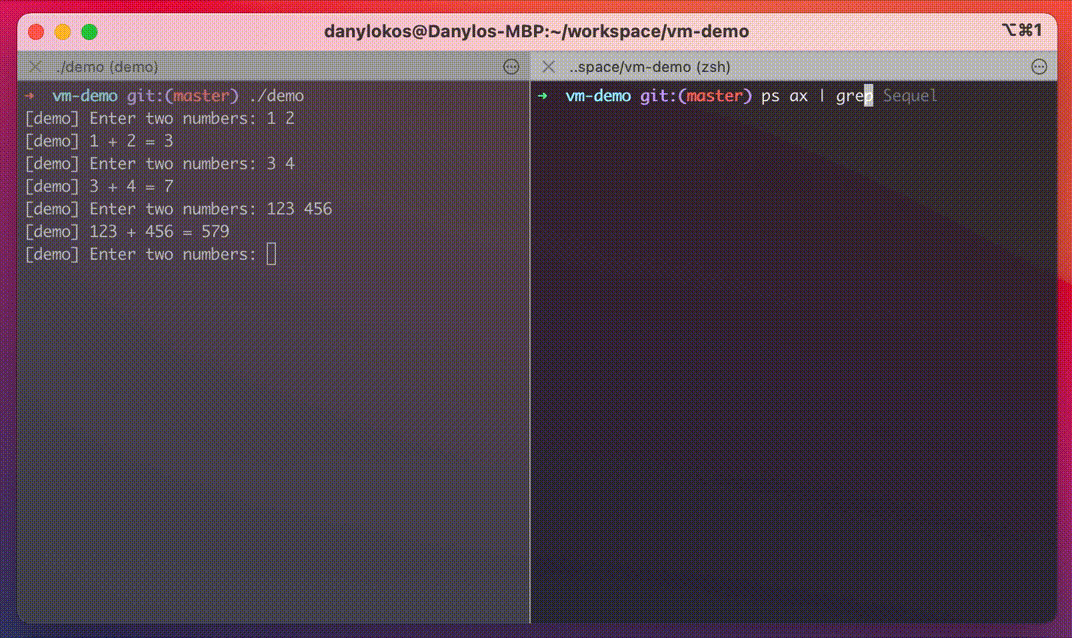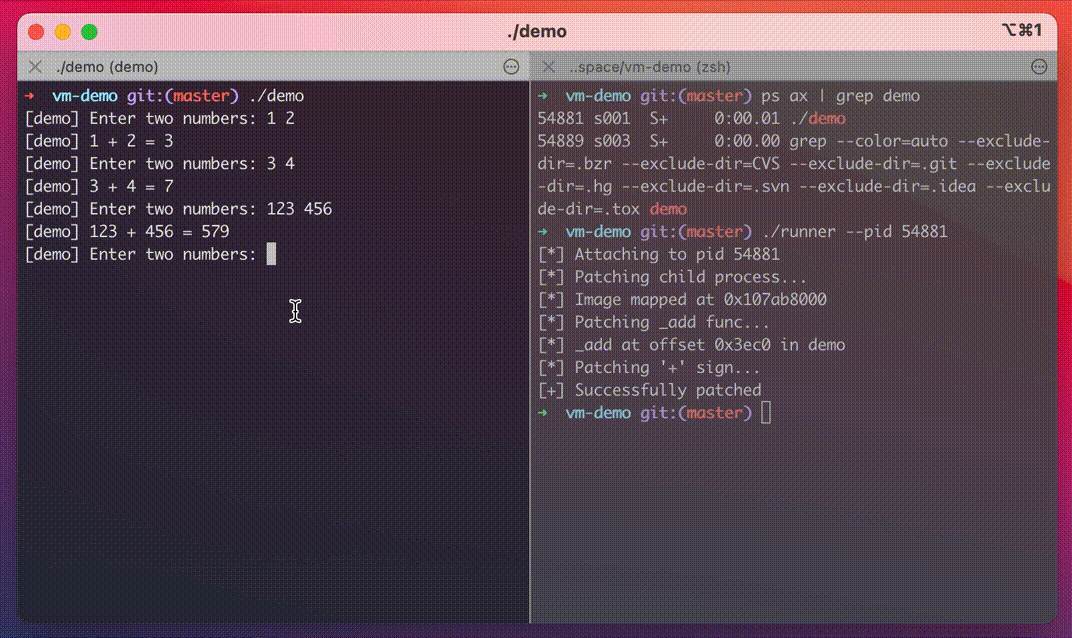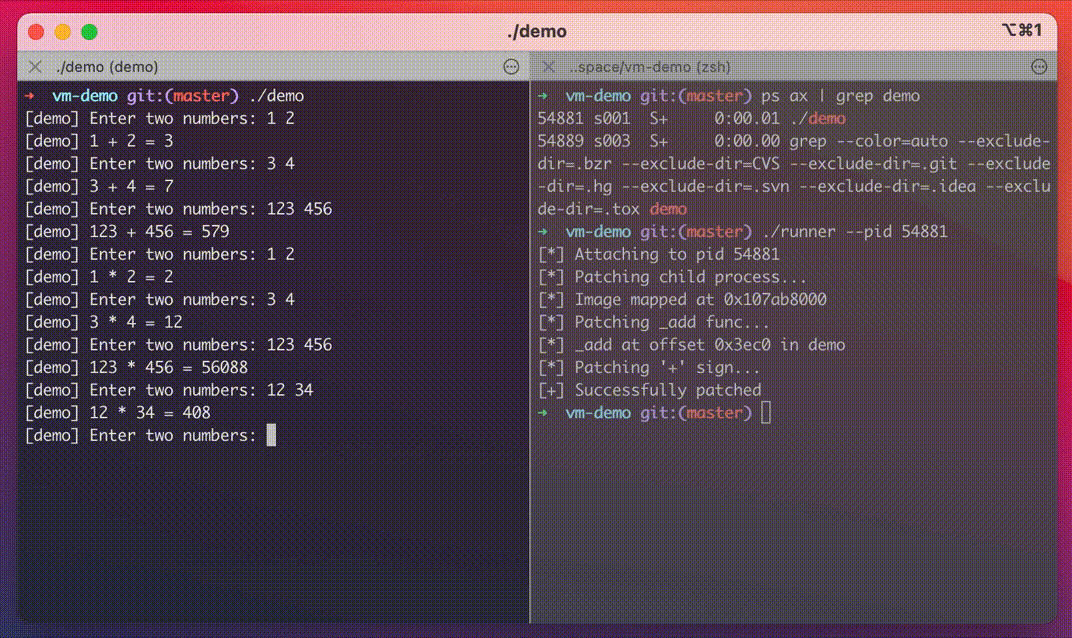
Demo
In this demo, you can see that our program performs addition on two provided integers, but after applying the patch, it starts multiplying them.